
Auto-Scaling Won’t Save You
The myth of infinite serverless scale — and what to do instead.

Serverless Scales. Your App Still Crashed.
It starts with a spike — maybe your app gets featured in a newsletter, or your product hits the front page of Hacker News. Suddenly, thousands of users flood your service. But you're ready, right? You're serverless. AWS Lambda will scale up! DynamoDB has on-demand mode!
Then… things slow down. Requests hang. Timeouts increase. Your dashboard goes from green to orange to red. Your app, once full of promise, is now full of users who can’t do anything.
What happened?
Serverless scaled but your problems scaled faster.
You didn’t hit your compute limit — you hit your design limit.
It's true—Lambda will happily launch thousands of execution environments up to your regional concurrency quota, but the databases behind those Lambdas obey physics.
A DynamoDB partition tops out at 3,000 RCU / 1,000 WCU.
An OpenSearch shard melts once the CPU stays pegged.
So when we switched on full-text search during a product launch, traffic spiked, hot partitions formed, and the cluster face-planted.
Your System's Breaking Point, in Plain English

Let’s break this down with a metaphor: imagine your database is a kitchen sink. If you pour water into it faster than it drains, eventually it overflows.
That’s overload.
In technical terms, it’s when the incoming rate of requests exceeds the outgoing rate your system can process. For a short time, maybe a queue can absorb the excess — like a sponge. But sustained overload? That’s when your systems start failing in very real ways.
Welcome to Your Unscalable Hell
When systems overload, a few things happen — none of them good.
Latency climbs. Suddenly, even simple requests feel sluggish.
Resources exhaust. Memory fills up. Connections max out.
Crashes cascade. One service slowing down triggers failures in others.
Retry storms begin. Your code keeps asking nicely. The platform keeps charging.

In serverless environments, this can get expensive fast. Lambdas don’t fail silently — they fail loudly and at scale. And every retry, every timeout, every re-invocation is a billable event.
Worst of all, when everything’s on fire, you still have to ask:
If you can’t serve everyone… who gets dropped?
Why Queues Don’t Save You
Your first instinct may be to go with classic plumber logic—“add bigger sinks”, so you add more memory or bigger queues but that doesn’t fix it, but in reality it doesn’t solve anything — it just takes longer to overflow.
As Fred Hebert puts it: queues don’t fix overload — they delay it. And that delay can make recovery even harder when the inevitable crash comes.
Fred Hebert’s seminal essay explains why that fails: queues merely hide overload until the collapse is total.
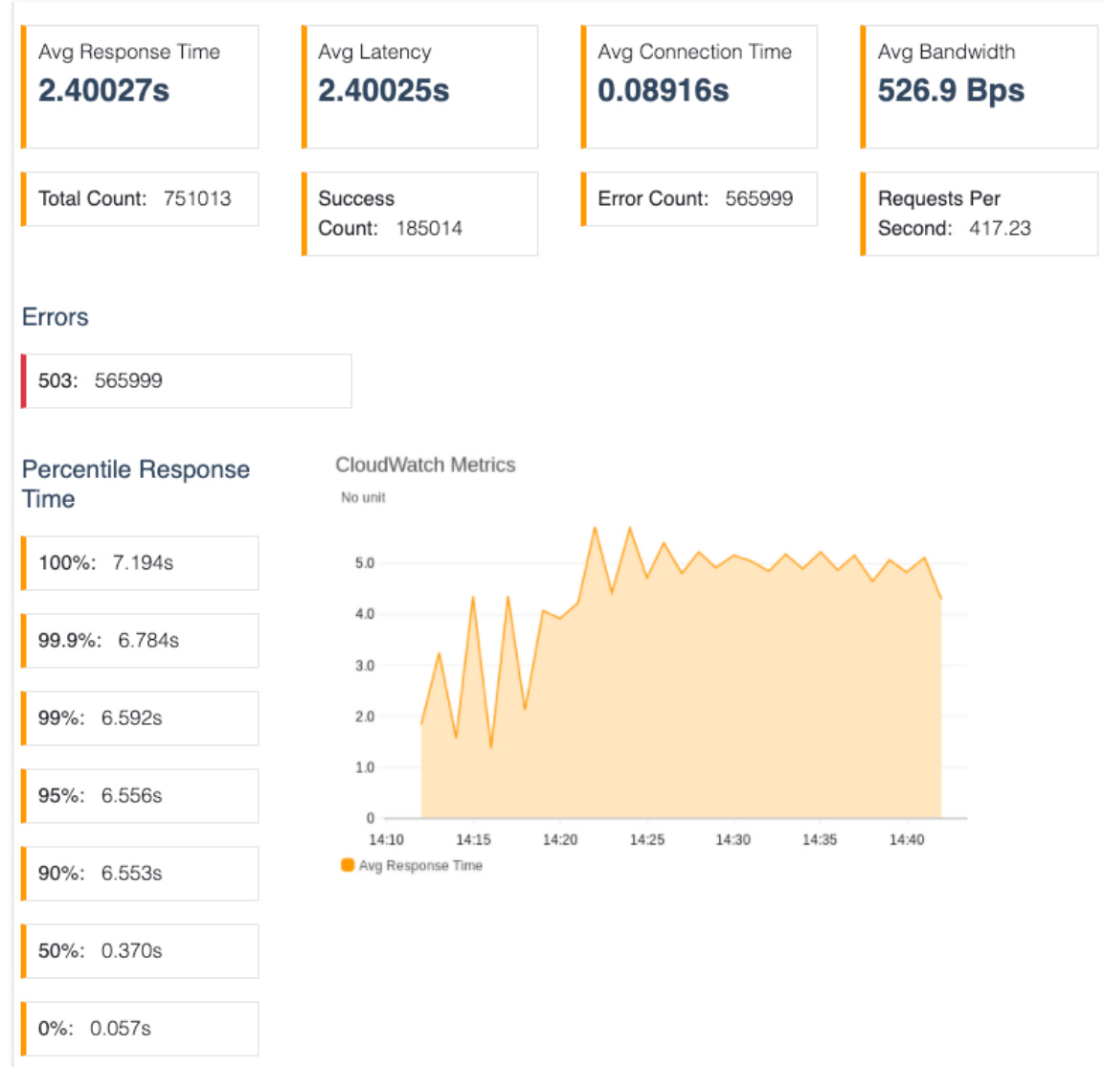
Some basic load tests paint a clear picture:
With no shedding, 75% of requests time out (565,999 / 751,013) and mean latency balloons past two seconds
What can we do?
Little’s Law: The Ancient Formula
L=λW
“To tame overload, you must observe it.”
This is Little’s Law. As wait time (W) rises, queue length (L) also rises.
The lesson: Latency is the universal, storage-agnostic early-warning signal.
Towards a Better Serverless Solution
In our tests, what we needed was a gate in front of the sink—but our constraints forbade new infrastructure, so instead we embedded a load-shedder inside every Lambda. Here was the basic idea:
Latency probe: Each invocation records its own response time.
Tiered shedding: Deterministically drop more traffic as latency crosses 500 ms, 600 ms, 1 s
Deterministic hashing: The same user either always gets through or always sees a polite 503, avoiding a roulette UX (Google SRE recommends deterministic subsetting for similar reasons).
CoDel-style minimum window: Use the minimum latency in a short window, not the average, to ignore random spikes; this borrows from the CoDel AQM algorithm.
With our new design active, mean p95 latency dropped dramatically from 2 seconds to 0.24 s while filling over 10x more requests per second.
How the Pros Handle Traffic Tsunamis

What these experiments show is that you can’t wish away overload — but you can handle it with grace. Here’s how modern systems do it:
Rate Limiters:
These control how fast requests come in. Think of it as metering traffic before it hits your service. Simple, effective, but often too blunt when load is unpredictable.Load Shedders:
These act in real-time, dropping excess requests based on the current system health. Smart shedders consider latency, user identity, or request type to make informed decisions about what to drop — and what to serve.Circuit Breakers:
When a downstream system is failing, circuit breakers prevent your service from repeatedly calling it. It’s like saying, “Let’s stop poking the broken thing until it recovers.”
Each one has a role. But in practice, you’ll need a combination of the three — especially under unpredictable or spiky load.
The Whipsaw: When Serverless Bites Back
In our case, a heavier load (50x50 virtual users) exposed a new failure mode: latency graphs began to oscillate every four minutes.
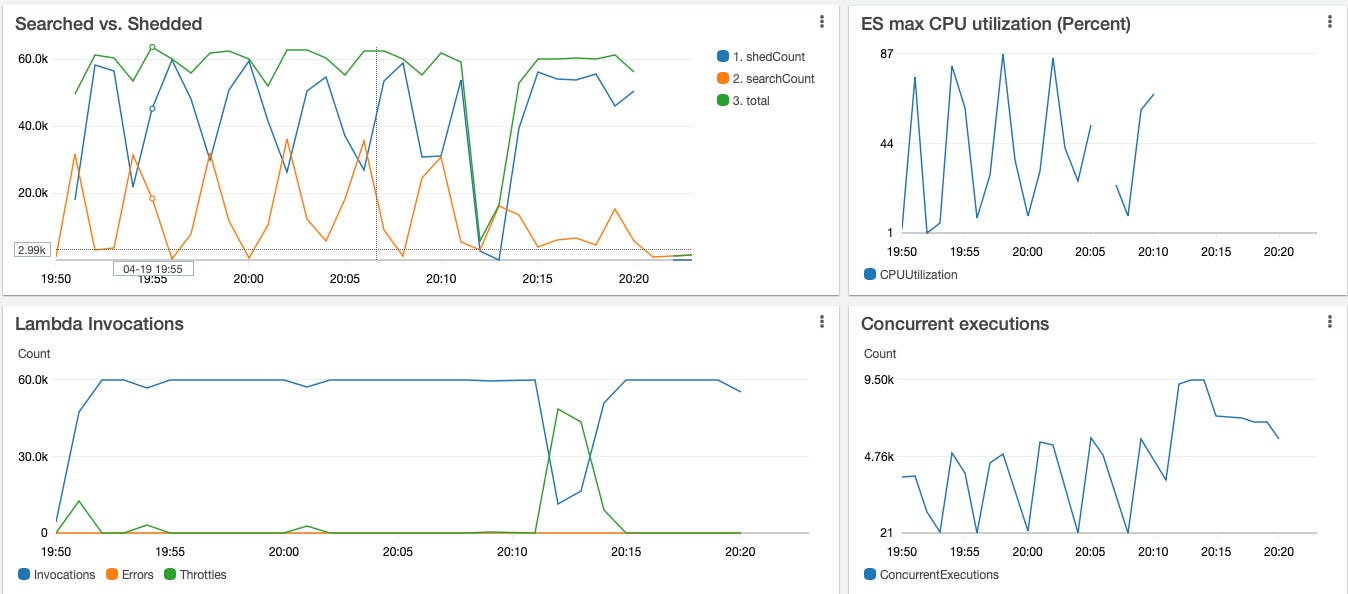
Root cause: Each Lambda kept only its own 10-sample history. During a surge, AWS added thousands of brand-new Lambdas with no history, so some thought the system was healthy while others screamed “shed 100%!”—a classic positive feedback loop.
So You Built a Lambda Ferrari With No Brakes

Handling overload in a traditional monolith? Hard. Handling it in a serverless, stateless, auto-scaling environment? Tricky.
Here’s why:
Little persistent state. Where do you track how overloaded you are? As we see above Lambda doesn’t remember enough between invocations.
No shared memory. Multiple instances, cold starts, different execution contexts — there’s no single “overload gauge” to watch.
Latency is misleading. It fluctuates with cold starts, I/O jitter, and concurrent invocations.
These are real engineering hurdles. But they don’t mean you’re helpless — just that you’ll need smarter tools and more creative thinking.
Smarter Decisions Under Pressure

Imagine if your system could:
Measure how slow it’s getting — and react instantly.
Drop requests intelligently, based on how valuable or resource-heavy they are.
Apply different rules to different groups — VIP users vs. anonymous ones.
Control all this without deploying new code, even during a live incident.
This isn’t magic. It’s just smarter load shedding.
Instead of all-or-none, you can define tiers:
Latency creeping up?, shed 10% of low-priority requests.
Getting worse?, shed 30%, then 60%.
Going nuclear? shed everything but the most critical traffic.
Even better, choose how to shed:
Random shedding: drop requests at random.
Deterministic shedding: always drop the same users or device classes, so their fallback paths activate predictably.
All of this can happen in milliseconds, close to the edge — and even be used within individual Lambda invocations. It just requires the right tooling and the right plan.
Real Experiments, Real Lessons

We tested these ideas in real systems — and the results were eye-opening.
Without protection, our services drowned under load: skyrocketing timeouts, API Gateway throttles, and 10,000+ concurrent Lambda invocations burning through budget.
With load shedding, even aggressive spikes were manageable. Latency stayed within bounds. Errors were intentional, not chaotic.
Fine-tuning helped too:
Smaller averaging windows made detection more responsive.
Deterministic shedding avoided surprise outages for key users.
Using DNS-based config meant we could adjust in real time, without redeploying.
Lesson learned: early, smart, intentional shedding works better than panicked retries and prayer.
What We Actually Learned—Five Key Take-aways
Compute bursts expose database limits. Virtually all architectures have a drain.
Queues / memory / extra compute does not solve overload. Back-pressure or drops need to be applied before the hot component.
Latency is the canary. Little’s Law turns milliseconds into queue depth.
Shedding should be deterministic and tiered. Random 50x works in chaos engineering, not in production UX.
State must be shared—or centrally coordinated. A tiny Redis (or purpose-built service) holding 16 bytes per endpoint beats thousands of Lambdas guessing in the dark. Ironically, that “one extra server” often reduces cost by preventing runaway concurrency.
You’re Not “Cloud-Native” If You Can’t Survive a Spike
Here’s the uncomfortable truth: serverless doesn’t mean resilient.
You still have to plan. You still have to think about overload. You still have to make tradeoffs.
But the good news? You don’t have to guess. You don’t have to accept random failure. You can design your system to stay graceful under pressure — and even recover faster when things go sideways.
So next time you're preparing for “beast mode” traffic, ask yourself:
Are you building for infinite scale?
Or are you building for reality?
Where We’re Going Next
We broke our “no infra” vow and prototyped a Redis-based coordinator. It fixed oscillations but quickly became the new bottleneck at ~100k operations/s—about an order of magnitude below our traffic goal. Our next article will show how Ratelimitly removes these barriers.
Stay tuned. Your Lambdas may thank you.
Selected References
AWS Lambda concurrency docs
Little’s Law (Wikipedia)
“Queues Don’t Fix Overload,” F. Hebert
Metal Toad on concurrency cost trade-offs
Google SRE book on deterministic subsetting
CoDel AQM algorithm
AWS knowledge-base: OpenSearch high CPU
AWS blog: Lambda cold-start & SnapStart
DynamoDB partition limits
AWS blog: hot partitions and split-for-heat